R을 활용한 당뇨병 데이터 분류 분석
보고서는 Kaggle에 제공된 "Pima Indians Diabetes Database" 데이터를 사용하여, 당뇨병 여부를 정확히 예측하는 최적의 분류 모델을 찾기 위한 분석을 수행합니다. 또한 시각화 기법을 활용하여 데이터 특성을 시각적으로 이해하고자 합니다.
데이터 소개 및 탐색적 분석
- 데이터 출처
- 캐글(Kaggle): Pima Indians Diabetes Database
- 데이터 구성
변수명설명데이터 타입
| Pregnancies | 임신 횟수 | numeric |
| Glucose | 포도당 농도 | numeric |
| BloodPressure | 혈압 수치 | numeric |
| SkinThickness | 피부 두께 | numeric |
| Insulin | 인슐린 수치 | numeric |
| BMI | 체질량 지수 | numeric |
| DiabetesPedigreeFunction | 당뇨병 혈통 지수 | numeric |
| Age | 나이 | numeric |
| Outcome | 당뇨병 여부 (1: 당뇨병, 0: 정상) | factor |
- 데이터 로딩 및 기본 탐색
df <- read.csv("diabetes.csv")
str(df)
summary(df)
Veiw(df)

- 결측치 및 이상치 확인
boxplot(df)

- 데이터 시각화 (분포 탐색)
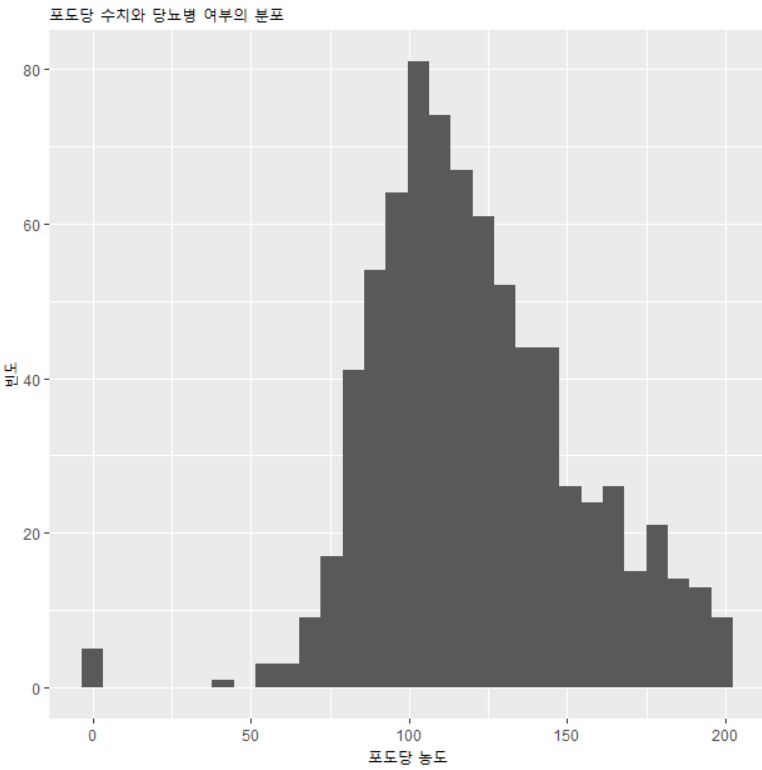
포도당 수치에 따른 당뇨병 분포를 확인하는 데이터를 탐색합니다.
library(ggplot2)
ggplot(df, aes(x=Glucose, fill=Outcome)) + geom_histogram(position="dodge", bins=30) + labs(title="포도당 수치와 당뇨병 여부의 분포", x="포도당 농도", y="빈도")
데이터 전처리
- 결측치 확인
colSums(is.na(df))

- 목표변수 데이터 타입 설정
df$Outcome <- as.factor(df$Outcome)
- 데이터 분할(Train/Test) 7:3
set.seed(123)
library(caret)
trainIndex <- createDataPartition(df$Outcome, p=0.7, list=FALSE)
train <- df[trainIndex,]
test <- df[-trainIndex,]
모델링 및 성능 평가
- 모델 1: 로지스틱 회귀(Logistic Regression)
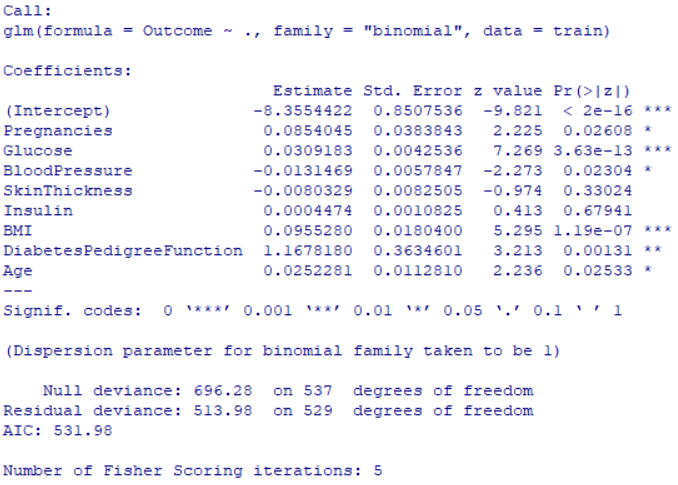
log_model <- glm(Outcome ~ ., data=train, family="binomial")
summary(log_model)
# 예측 및 성능 평가
pred_log <- predict(log_model, test, type="response")
pred_class <- ifelse(pred_log > 0.5, 1, 0)
# 혼동행렬과 정확도
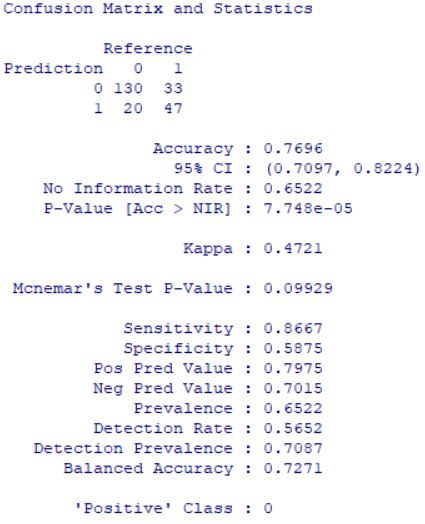
cm_log <- confusionMatrix(as.factor(pred_class), test$Outcome)
cm_log
- 모델 2: 랜덤 포레스트(Random Forest)
library(randomForest)
rf_model <- randomForest(Outcome~., data=train, ntree=100)
print(rf_model)
# 예측 및 평가
pred_rf <- predict(rf_model, test)
cm_rf <- confusionMatrix(pred_rf, test$Outcome)
cm_rf

모델 성능 비교 시각화
각 모델의 성능을 시각화하여 직관적으로 비교합니다.
accuracy <- data.frame( Model=c("Logistic Regression", "Random Forest"), Accuracy=c(cm_log$overall['Accuracy'], cm_rf$overall['Accuracy']) )
accuracy

ggplot(accuracy, aes(x=Model, y=Accuracy, fill=Model)) + geom_bar(stat="identity", width=0.5) + ylim(0,1) + geom_text(aes(label=round(Accuracy,2)), vjust=-0.3, size=4) + labs(title="모델별 정확도 비교", x="모델", y="정확도(Accuracy)") + theme_minimal()
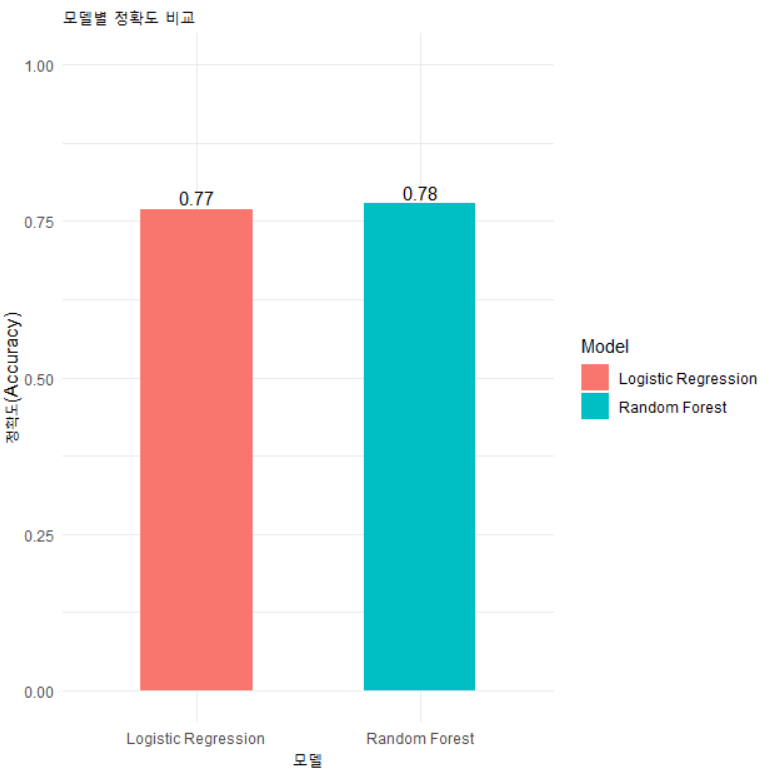
| 모델 | 모델정확도(Accuracy) |
| 로지스틱 회귀 | 0.77 |
| 랜덤 포레스트 | 0.78 |
결론 및 제안사항
본 분석을 통해 다양한 분류 모델을 사용하여 당뇨병 여부를 예측하였습니다. 결과적으로 랜덤 포레스트(Random Forest) 모델이 더 우수한 성능을 나타냈으며, 78%의 정확도를 기록하였습니다.
세부적으로 살펴보면 다음과 같은 사항을 도출할 수 있습니다.
- 포도당 농도(Glucose), BMI(체질량지수), 나이(Age) 등이 당뇨병 발생 여부를 예측하는 데 매우 중요한 영향력을 미쳤습니다.
- 로지스틱 회귀 모델은 간단하면서도 준수한 성능을 보였으나, 비선형 패턴이 존재하는 경우 성능이 떨어지는 한계가 나타났습니다.
향후 개선을 위한 제안사항
- 데이터의 수를 확대하여 학습 데이터의 품질을 높이고 모델의 일반화 성능을 향상시켜야 합니다. 특히 다른 인종이나 지역의 환자 데이터를 추가로 확보하여 모델의 보편적 적용 가능성을 높일 필요가 있습니다.
- 모델의 성능 개선을 위해 하이퍼파라미터 튜닝(Grid Search 또는 Random Search)을 수행하여 최적의 성능을 이끌어낼 수 있도록 권장합니다.
- 의료진이나 현장 사용자를 위한 예측 프로그램 또는 웹 애플리케이션의 개발을 고려하여, 실제 의료 환경에서 활용 가능성을 높일 필요가 있습니다.
분석 결과의 시사점
본 분석은 의료 현장에서 다음과 같은 중요한 시사점을 제공합니다.
(1) 의료적 시사점
- 환자의 혈당 수치와 체질량 지수 등 기본적인 임상 지표만으로도 높은 정확도의 당뇨병 예측이 가능하다는 사실이 입증되었습니다. 따라서 현장에서 간단한 건강검진 결과만으로 당뇨병 고위험군을 조기에 선별할 수 있는 효율적인 프로세스를 구축할 수 있을 것입니다.
(2) 데이터 기반 의사결정 강화
- 본 분석에서 도출한 랜덤 포레스트 모델은 데이터 기반의 정량적 의사결정을 가능하게 합니다. 의료진은 모델 예측 결과를 참고하여 환자의 상태를 보다 신속하고 정확히 판단할 수 있을 것입니다.
(3) 맞춤형 의료 서비스의 가능성
- 본 결과는 개인 맞춤형 의료 서비스로의 확장 가능성을 보여줍니다. 환자별 상세한 데이터 분석과 모델의 정기적 업데이트를 통해 개인의 특성에 최적화된 예방 및 관리 전략을 수립할 수 있을 것입니다.
(4) 공중보건적 가치
- 지역사회 단위에서 당뇨병 위험군을 선별하고 관리할 수 있는 효과적인 도구가 될 수 있으며, 이는 국가 차원의 의료비 절감과 공중보건의 질 향상에 기여할 것입니다.
'IT관련' 카테고리의 다른 글
| 수면 시간과 스트레스가 수면의 질에 어떤 영향을 줄까? ( + R 회귀분석 ) (0) | 2025.04.09 |
|---|---|
| 중선형 회귀모델 , 교육, 평판, 여성 비율로 알아보는 연봉 예측 모델 ( +R코드 ) (0) | 2025.04.07 |
| R로 회귀 모델 만들기 : cars 주행 속도와 제동 거리 (0) | 2025.04.03 |
| GDP로 보는 대한민국의 변화 – 경제성장, 출산율, 기대수명의 상관관계( + R코드) (0) | 2025.04.02 |
| 국내 인구동향 변화 분석 (1970~2023) ( + R코드 ) (0) | 2025.04.01 |



